HADOOP

Purpose
The purpose of Hadoop is to efficiently store and process large datasets, ranging from gigabytes to petabytes of data. Instead of relying on a single large computer, Hadoop clusters multiple computers to analyze massive datasets in parallel, enhancing processing speed and scalability.
Data Storage System
The Hadoop Distributed File System (HDFS) serves as the core data storage system for Hadoop applications. It utilizes a Name-Node and Data-Node architecture to create a distributed file system, enabling efficient access to data across scalable Hadoop clusters.
At Connexicatech, we offer unparalleled expertise in Hadoop and AWS, allowing us to provide valuable assistance in deriving cost-effective benefits from your data infrastructure. Our focus is on enhancing your AWS experience while providing comprehensive guidance and support throughout your data management journey.

Hadoop Use Cases:
- Financial Services: Analyzing risk, building investment models, and creating trading algorithms.
- Retail: Analyzing structured and unstructured data to understand customer behavior and improve customer service.
- Energy Industry: Predictive maintenance using IoT data and analytics.
- Telecommunications: Predictive maintenance, network optimization, and customer behavior analysis for service offerings.
- Public Sector: Disease outbreak prediction, tax fraud detection, and other data-driven initiatives.
At Connexica Technologies Pvt. Ltd., we leverage Hadoop’s capabilities to provide efficient data storage and processing solutions. Our expertise in AWS allows us to deliver cost-effective benefits and guide you through every step of your data management journey.
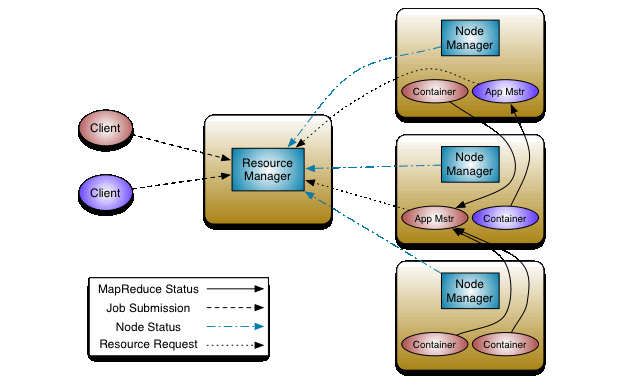
YARN Architecture
YARN (Yet Another Resource Negotiator) was introduced in Hadoop version 2.0 to address resource scheduling issues that existed in version 1.0, particularly in the MapReduce framework. In version 1.0, MapReduce jobs were divided into tasks (Map tasks, Reducer tasks) and executed on DataNode machines in the cluster. Each DataNode machine had a set number of slots (map slots, reducer slots) for task execution. The JobTracker managed slot reservations for job tasks and monitored their execution.
If a task failed during execution, the JobTracker reserved another slot and re-attempted the task. It also handled the cleanup of temporary resources and made the reserved slot available for other tasks.
Hadoop’s effectiveness, scalability, and strong support from large vendor and user communities make it a popular choice for big data programs, establishing it as a standard in the field.
Benefits
Millions of Files
Store millions of extensive files, each exceeding tens of gigabytes in size, with filesystem capacities expanding to tens of petabytes.
Access to many Files
Prioritize optimization for large, continuous reads and writes over quick access to numerous small files.
Inexpensive commodity
Implement a scale-out model utilizing cost-effective commodity servers with internal JBOD (Just a Bunch Of Disks) instead of RAID to achieve extensive storage capacity at scale.
Application level
Achieve high availability and throughput by replicating data at the application level. This approach supports the functionality and scalability needs of MapReduce processing.